


重磅 | 深度学习嵌入式移植,让其真正走进你的生活
深度学习在这十年,甚至是未来几十年内都有可能是最热门的话题。虽然深度学习已是广为人知了,但它并不仅仅包含数学、建模、学习和优化。算法必须在优化后的硬件上运行,因为学习成千上万的数据可能需要长达几周的时间。因此,深度学习网络亟需更快、更高效的硬件。
众所周知,并非所有进程都能在CPU上高效运行。游戏和视频处理需要专门的硬件——图形处理器(GPU),信号处理则需要像数字信号处理器(DSP)等其它独立的架构。人们一直在设计用于学习(learning)的专用硬件,例如,2016年3月与李世石对阵的AlphaGo计算机使用了由1920个CPU和280个GPU组成的分布式计算模块。而随着英伟达发布新一代的Pascal GPU,人们也开始对深度学习的软件和硬件有了同等的关注。而在现实生活中,也越来越需要一些更轻巧更便捷的嵌入式设备,来更便捷的实现深度学习框架的移植,并更好的为人服务。移动端不用做training,主要是要做propagating, 所以问题应该集中在移动端能不能放下并运行更大的network。
下面是开发者广泛使用的几种移动端开发设备。
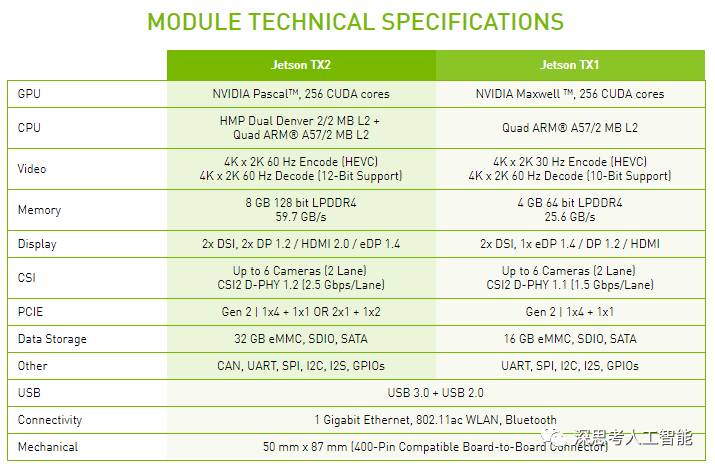
1、NVIDIA Jetson Tx1(Tx2)

TX1(TX2)可CUDA 8.0 (8.0.56) Toolkit,cuDNN v5.1,VisionWorks 1.6,OpenCV 2.4.13等一批最新的软件包,更好的方便开发人员将现有的网络快速的移植到嵌入式设备中。
软件包说明文档:
http://docs.nvidia.com/jetpack-l4t/index.html#developertools/mobile/jetpack/l4t/3.0/
最新的TX2采用了NVIDIA的Pascal架构,拥有更快的速度,更低的功耗,而且支持最新的H.265图像压缩技术。
caffe移植
https://github.com/jetsonhacks/installCaffeJTX1
https://github.com/jetsonhacks/installCaffeJTX2
faster RCNN移植
http://elinux.org/Jetson_TX1
https://devtalk.nvidia.com/default/topic/1004976/faster-r-cnn-on-jetson-tx1/
tensorflow移植
https://github.com/jetsonhacks/installTensorFlowTX1
https://github.com/jetsonhacks/installTensorFlowTX2
2、手机安卓, IOS
现在只支持CPU版本,毕竟手机的GPU版本不能统一,基本没有什么框架可以支持所有型号的GPU,值得注意的是,当前,嵌入式设备(手机等)的GPU,实际上要比CPU要慢得多。
(1)Caffe的移动端编译项目
caffe(命令式框架)算是在国内最流行的深度学习开源框架,使用它进行商业,研究的人很多。对于移动端的实现,也有开源项目对caffe进行了移植。
项目连接如下:
android-lib
android-demo
(2)mxnet的移动端项目
mxnet(符号式框架)主要也是几个中国人一起发起和维护的深度开源项目,足够灵活,速度足够快,扩展新的功能比较容易,内存复用,很有潜力成为未来优秀的深度项目。最关键的是,mxnet本身提供了对android,iOS移动端的的支持。而且最近,mxnet已经 被 Amazon AWS 选为官方深度学习平台。
android-lib
android demo
1) mxnet明显从本身特点就比caffe更适合移动端,因为依赖少,内存要求少,对于android 性能变化大的手机,通用性更高。
2) mxnet需要先使用ndk交叉编译项目中的amalgamation,可以根据自己的需求,修改jni中的接口,然后,编译好的动态链接库替换掉android demo 中的。不过在编译过程中我遇到了很多的问题,编译成功也不是很简单的事情。
3)mxnet提供了对caffe 模型的支持,那么即使你用caffe训练好的模型,也可以通过提供的工具讲其进行转化json格式,然后就可以在mxnet 上使用,自然也可以在移动端使。
(3)Torch-Android
torch android
(4)tensorflow的移动端项目
Google 开源的深度学习框架 tensorflow 成为2016年最受欢迎的深度学习框架之一。tensorflow 除了支持 pc 端外,还较好的支持了 android,iOS 移动端平台。移动端作为现在互联网的终端主宰,tensorflow 毫无疑问地会引起移动互联网行业的广泛关注。深度学习在2016年的火爆,以及移动终端的主宰地位,作为程序员的我们,不玩玩 tensorflow 简直就 out 了。
android build
https://depthlove.github.io/2017/01/16/tensorflow-iOS-application/
(5) DeepLearningKit
DeepLearningKit 是针对 iOS、OS X 和 tvOS 的开源深度学习框架。
http://deeplearningkit.org/tutorials-for-ios-os-x-and-tvos/tutorial-image-handling-in-deeplearningkit/
以上框架都是很流行,很通用的,自然带来的问题就是,对于手机android、ios系统来说过于庞大,所以,如果要实现一个相对单一的深度算法,那么,我们必须需要对其进行瘦身。移动端在不需要实时的项目中,对gpu的要求不高,但是如果能提供对gpu的支持,那么项目的性能自然可以提高很多,但是,大部分手机,gpu不支持cuda,所以以上介绍的深度框架,只能使用cpu-only模型进行前向传播。
(6)CoreML
CoreML是第一个较完善的手机端人工智能框架,利用它可以做出创新的功能。

和Tensorflow、Caffe等深度学习框架不同,CoreML是完全聚集于在设备端本地进行深度学习推理的框架,而其它框架除了支持本地设备端同时也支持云端,能够推理也支持训练。
集中力量的一个结果是CoreML性能更优。苹果宣传Inception v3速度是Tensorflow的6倍,这是通过MetalAPI对于GPU能力充分利用的结果。
另一个结果是,CoreML看起来更方便使用。苹果很聪明的定义了一个标准的模型格式(.mlmodel),提供了流行的框架模型到该格式的转换工具,比如你可以将你的Caffe模型转换成CoreML的模型格式。这样就可以利用各个模型的训练阶段,而不像TensorflowLite只能使用Tensorflow模型。模型训练好了之后,只要拖放到XCode中就可以使用,苹果甚至把接口的Swift代码都给你生成好了,非常方便。
3、FPGA
英伟达的GPU在深度学习硬件市场上一直处于领先地位。英伟达以其大规模的并行GPU和专用GPU编程框架CUDA主导着当前的深度学习市场。但是越来越多的公司开发出了用于深度学习的加速硬件,比如谷歌的张量处理单元(TPU/Tensor Processing Unit)、英特尔的Xeon Phi Knight's Landing,以及高通的神经网络处理器(NNU/Neural Network Processor)。像Teradeep这样的公司现在开始使用FPGA(现场可编程门阵列),因为它们的能效比GPU的高出10倍。

Xilinx出的一款开发板,将ATM和FPGA集成到一起,ZYNQ-7000系列开发套件
https://china.xilinx.com/products/boards-and-kits/ek-z7-zc706-g.html
FPGA更灵活、可扩展、并且效能功耗比更高。 但是对FPGA编程需要特定的硬件知识,因此近来也有对软件层面的FPGA编程模型的开发。
此外,一直以来广为人所接受的理念是,适合所有模型的统一架构是不存在的,因为不同的模型需要不同的硬件处理架构。 而研究人员正在努力,希望FPGA的广泛使用能够推翻这一说法。
总之,大多数深度学习软件框架(如TensorFlow、Torch、Theano、CNTK)是开源的,而Facebook最近也开放其 Big Sur 深度学习硬件平台,因此在不久的将来,我们应该会看到更多深度学习的如实硬件设备。
深思考人工智能,是一家专注于人工智能核心算法及专用芯片的科技公司。目前主要产品为ideepwise AI Robot Service底层服务系统、基于该底层服务系统的IDeepwise人工智能“医疗大脑”和二代人工智能机器人系统及FPGA AI加速芯片。主要面向医疗、汽车及智能家居三大领域提供人工智能产品及服务解决方案。
更多精彩扫描二维码





